
If you work with business continuity (BC), disaster recovery (DR), or high availability (HA), you’re bound to run across the following terms:
- Recovery Point Objective (RPO)
- Recovery Time Objective (RTO)
- Recovery Time Actual (RTA)
- The RTA-RTO Gap
Because these acronyms are so similar, it’s easy to confuse them with each other. Here’s a primer on what each of these terms mean and how they can help your IT shop in BC, DR, and HA planning.
The Big Picture
Visually, RTO, RPO, and RTA relate to each other in the following way:
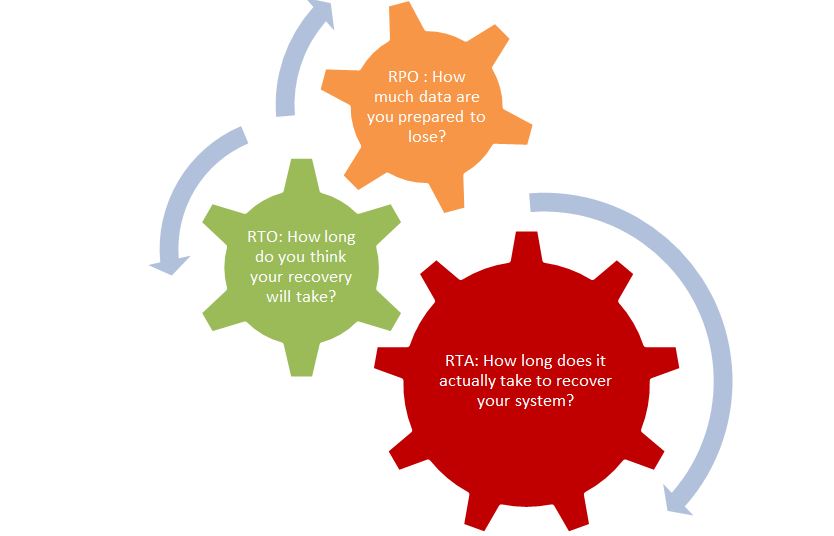
RPO, RTA, and RTO are the terms management uses to communicate goals for a BC/DR/HA system (click to enlarge)
Think of RPO, RTO, and RTA are being three gears in the same machine.
Each gear helps move your BC/DR/HA strategy in the right direction. They all work together in the following ways to define how data is synchronized between your source and target machines and how long it takes to switch production from your source to your target machine.
 Recovery Point Objective (RPO)
Recovery Point Objective (RPO)
A Recovery Point Objective (RPO) is the maximum time frame your organization is willing to lose data for, in the event of a major IT outage.
RPO provides a target for designing your BC/DR/HA solution.
For example, if you designate a RPO of 30 seconds, you would design your solution to synchronize data between your production/source and backup/target solution so that at any given moment, the data between the two boxes is no more than 30 seconds out of sync.
If your primary source machine fails, your organization would lose no more than the last 30 seconds of production system updates.
An RPO is a business decision as to how much current data (orders, invoices, inventory moves) the business is willing to risk if the production source system becomes unavailable.
Remember: an RPO is a design spec, not a statistic. You architect your BC/DR/HA solution around the RPO, build the solution to match the RPO, and then measure the solution’s performance against the RPO.
You won’t know if your actual recovery point will match your RPO unless you measure and adjust your system. Having an RPO of 30 seconds and achieving an RPO of 30 seconds are two different things.
The RPO can also be shrunk over time as you install, measure, and tweak your solution to create tighter synchronization between source and target.
 Recovery Time Objective (RTO)
Recovery Time Objective (RTO)
A Recovery Time Objective (RTO) refers to how quickly you can switch from your production source machine to your target backup machine, in the event of an emergency.
Like your RPO, an RTO is also a target, not a statistic. In the event of a major outage on a production box, it states your goals for restarting the system on a backup machine or partition.
For example, if you designate an RTO of two hours, your goal is to restore service within two hours in the event of a production system failure.
Your RTO time can vary depending on the type of BC/DR/HA solution you’re using.
For clustered solutions, recovery to a backup machine can be almost instantaneous. For manually switched solutions where you need to execute run book steps to redirect production to your backup, it can take several hours. And for rebuilds where you have to perform a bare metal restore, it can take a day or longer.
An RTO is a business decision that will affect your solution choice.
There’s an inverse relationship between what it costs to implement a BC/DR/HA solution and what it costs to run that same solution in an emergency.
In general, the less expensive the solution, the more expensive it will be to implement that system in an emergency. It doesn’t take much to back up your systems but in a crisis, an old-fashioned bare metal restore to a new machine could take a day or more (note: newer virtualization technologies can significantly reduce this gap). It may take tens (or hundreds) of $1000s of dollar to set up a clustering system or a replicated system but in a crisis, a target system can be quickly activated reducing the outage’s effect on your business.
So choose your RTO carefully and understand that it is intimately tied to the tolerance your company or client has for restoring service after an outage.
 Recovery Time Actual (RTA) and the RTO-RTA Gap
Recovery Time Actual (RTA) and the RTO-RTA Gap
Recovery Time Actual (RTA) is the actual amount of time it takes to activate your BC/DR/HA solution in an emergency.
Unlike the RPO and RTO which are goals, an RTA IS a statistic.
For example, if you run a switch test to move production from your source to your target machine, the RTA will be the actual time it took to activate your target machine as your new production box.
Your RTA is the benchmark for how much time it actually takes to restore production to your target system, if the production system goes down for any reason whatsoever.
The RTA allows you to measure how effective your switch strategy is. It can only be computed during an actual switchover so having an RTA requires testing your switch strategy.
If there’s a significant gap between your RTO (goal) and RTA (actual), you’ll need to rework your switchover strategy to improve the time it takes to switch production from source to target.
The other thing to note is that when you perform regular switch tests, you can also gauge how effective your RPO is (how tightly your source and target machine data are in sync).
Putting RPOs, RTOs, and RTAs together
Taken together, these three statistics are management shorthand for how well your BC/DR/HA solution works.
- The RPO defines how closely source and target machine data is in sync. It’s your goal for how much data will be lost if your production suddenly disappears. RPO must be measured as you are replicating and as you switch production.
- The RTO defines your goal for how quickly production can be shifted to a target machine, in the event of a catastrophic failure.
- The RTA is the actual performance of your BC/DR/HA solution in transferring production to a target system, in the event of a failure. It must be tested on a regular basis to validate your RTO.
Properly communicated, your RPO, RTO, and RTA are valuable management tools for communicating your goals for your solution and how well you are doing in meeting those goals.

![]()
![]()
Related Posts
 Community Post: List of IBM i Content Providers
Community Post: List of IBM i Content Providers Historically Correct But…Things PureSystems Have in Common with the old AS/400 Systems
Historically Correct But…Things PureSystems Have in Common with the old AS/400 Systems Creating a URL for LinkedIn Activity Feeds
Creating a URL for LinkedIn Activity Feeds Creating a Twitter Search URL–Beginner’s Version
Creating a Twitter Search URL–Beginner’s Version Will Opening the CEC Cover Turn Off Your Power 7 System?
Will Opening the CEC Cover Turn Off Your Power 7 System? IT Jungle: A Complete Primer for Setting Up PC5250 SSL Connectivity
IT Jungle: A Complete Primer for Setting Up PC5250 SSL Connectivity